GitHub Copilot is an AI-powered code completion tool developed by GitHub in collaboration with OpenAI. It helps developers by suggesting code snippets, entire functions, and even generating documentation as they type, improving coding efficiency. Here's how it works and what it offers:
Key Features
Code Suggestions
- GitHub Copilot can suggest entire lines or blocks of code based on the context of your current coding task.
- It learns from the code you write and adjusts its suggestions accordingly.
Supports Multiple Languages
- Copilot supports a wide range of programming languages including Python, JavaScript, TypeScript, Ruby, Go, Java, C#, and more.
- It works across multiple frameworks and libraries.
Contextual Awareness
- It understands comments and context within the code. If you describe a function in a comment, Copilot can generate a full implementation.
- It’s capable of interpreting comments, variables, and even importing necessary modules automatically.
Integrated in Development Environments
- GitHub Copilot is available as an extension for Visual Studio Code (VS Code), making it easy to integrate into your existing workflow.
- It also works in other IDEs like JetBrains.
Learning from Open Source Code
- Copilot is trained on a vast amount of publicly available open-source code, helping it suggest relevant code patterns and solutions.
Limitations
- It doesn’t always generate perfect code, and in some cases, suggestions might need refinement.
- It can sometimes suggest code snippets that may have security vulnerabilities or outdated patterns, so developers need to verify the suggestions.
- Copilot doesn't have awareness of private code unless specifically trained or given access to it, so it’s privacy-conscious.
Ethical Considerations
- Since Copilot is trained on public repositories, some concerns have been raised about licensing, particularly whether the code snippets it generates might unintentionally include license-protected code.
How to Use GitHub Copilot
Installation
- You can install GitHub Copilot as an extension in Visual Studio Code by searching for "GitHub Copilot" in the Extensions marketplace.
Subscription
- As of 2023, GitHub Copilot requires a subscription, though it provides a free trial for users to test its features.
Workflow
- After installation, as you code in supported languages, Copilot will start suggesting code in real-time.
- You can accept suggestions by pressing
Tab, or cycle through multiple suggestions with keyboard shortcuts.
Example: Setting up and using "GitHub Copilot" and "GitHub Copilot Chat" extentions in VS Code.
Step1: Install the GitHub Copilot Extension
- Open VS Code.
- Go to the Extensions panel (on the sidebar or Ctrl+Shift+X).
- Search for "GitHub Copilot" and click Install.
- Search for "GitHub Copilot Chat" and click Install.
Step2: Sign in to GitHub
- After installing the extension, you'll be prompted to sign in to your GitHub account.
- Make sure your account has access to GitHub Copilot (it requires a paid subscription or a free trial).
Step3: Start coding
- Create a new file with an appropriate file extension (e.g. .js, .py, .java).
Please note while using first time, It will suggest you to install few essential plugins based on file you create (e.g. .java), which you should install.

You can type or ask by pressing CTRL+I and Copilot will generate code for your problem statement.
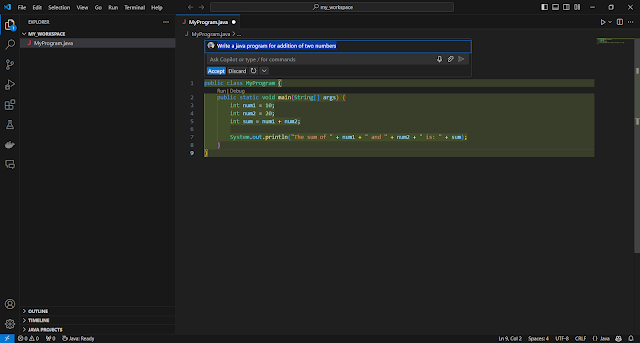
Copilot will start suggesting code, as you type. You can accept suggestions by pressing Tab key.

Copilot also suggest code for a comment. Just write a comment on a class and when you move curser inside class you will be suggested with a few codes where you can accept one.

You can get explanation of your code, press CTRL+I and type /explain and enter


👉 Similarly you can generate /doc, /tests, and also /fix the code by pressing CTRL+I and providing these paths.
GitHub Copilot Chat
👉 Open "GitHub Copilot Chat" window to chat with GitHub Copilot (an OpenAI LLM Codex)
Click on GitHub Copilot icon which is at right button in IDE -> show Copilot status menu -> GitHub Copilot Chat -> than start chatting
👉 Explain the code: Select the code and type /explain in Copilot Chat

👉 Debug the exception: Copy your exception from the console and paste in Copilot Chat.
👉 Fix the code: Open the code to fix and type /fix in Copilot Chat
👉 Generate unit tests: Select the method and type /tests in Copilot Chat.
👉 Get documentation: Select the code and type /doc in Copilot Chat.
👉 Review and refactor: Select the code and type like review and refactor in Copilot Chat.
👉 You can generate anything like exception handling class, etc for a specific code in Copilot Chat.
GitHub Copilot vs GitHub Copilot Chat
- Copilot provides real-time code suggestions to speed up your workflow, while Copilot Chat offers deeper interactions like answering specific questions, helping with debugging, and explaining code when needed.
- You can think of Copilot as a passive code-writing assistant and Copilot Chat as a more active, conversational partner.